
Künstliche Intelligenz ist auf dem Weg, in fast allen Lebensbereichen eingesetzt zu werden. Auch im Bereich der Personalauswahl gibt es verschiedene Entwicklungen, Mitarbeiter mit Hilfe intelligenter Algorithmen und Software auszuwählen und Unterstützung bei Personalentscheidungen zu geben (auch als „Robot Recruiting” bezeichnet).
In der Praxis haben sich jedoch viele dieser Ansätze als unbrauchbar erwiesen, wohingegen Algorithmen in zwei wenig beachteten Bereichen der Personalauswahl viel Potenzial bieten.
Inhaltsverzeichnis
Algorithmen oder Künstliche Intelligenz?
Nicht jeder Algorithmus (d. i. eine Rechenanweisung, also eine Formel, mit der man aus vorhandenen Daten neue Daten berechnet) basiert auf Prinzipien der Künstlichen Intelligenz. In der Personalauswahl werden schon seit Längerem Algorithmen eingesetzt, um Auswahlentscheidungen zu unterstützen.
Ein einfacher Algorithmus – Intelligenztests zur automatischen Bewerberauswahl
Im einfachsten Fall hat man eine einzelne Kompetenz, auf deren Basis Vorhersagen für den beruflichen oder schulischen Erfolg getroffen werden. Bekanntestes Beispiel ist „Intelligenz“ – mit Hilfe eines Intelligenztests kann man den späteren Erfolg in Schule, Studium und Beruf recht gut vorhersagen:

In der Abbildung ist der Zusammenhang zwischen einem Intelligenztest (der „Advanced Progressive Matrices“ Test von Raven, auf der X-Achse) und dem Schulerfolg (SAT ist ein schulischer Leistungstest in den USA, vergleichbar dem deutschen Abitur) aufgezeigt. Der Algorithmus ist hier sehr einfach: der Zusammenhang ist linear, je höher der Wert im Intelligenztest, desto besser das Ergebnis im SAT. Man sagt also auf Basis des Ergebnisses des Intelligenztests den schulischen und beruflichen Erfolg voraus:

Auch im beruflichen Bereich ist Intelligenz ein guter Prädiktor. Wenn man statt des SAT das spätere Einkommen oder den Hierarchielevel vorhersagen will, gelingt das ähnlich gut. Für das Recruiting hieße das, dass man sie bei der Einstellung einfach einen Intelligenztest machen lässt, um den Berufserfolg vorherzusagen – und nur diejenigen einstellt, die über einem bestimmten Grenzwert liegen. Sofern man eine große Anzahl von Bewerbern hat, von denen man schnell die am wenigsten geeigneten aussortieren will, ist ein Intelligenztest ein durchaus legitimes Verfahren zur Vorauswahl.
Ein komplexer Algorithmus – Intelligenz plus Persönlichkeitsprofil zur Auswahl
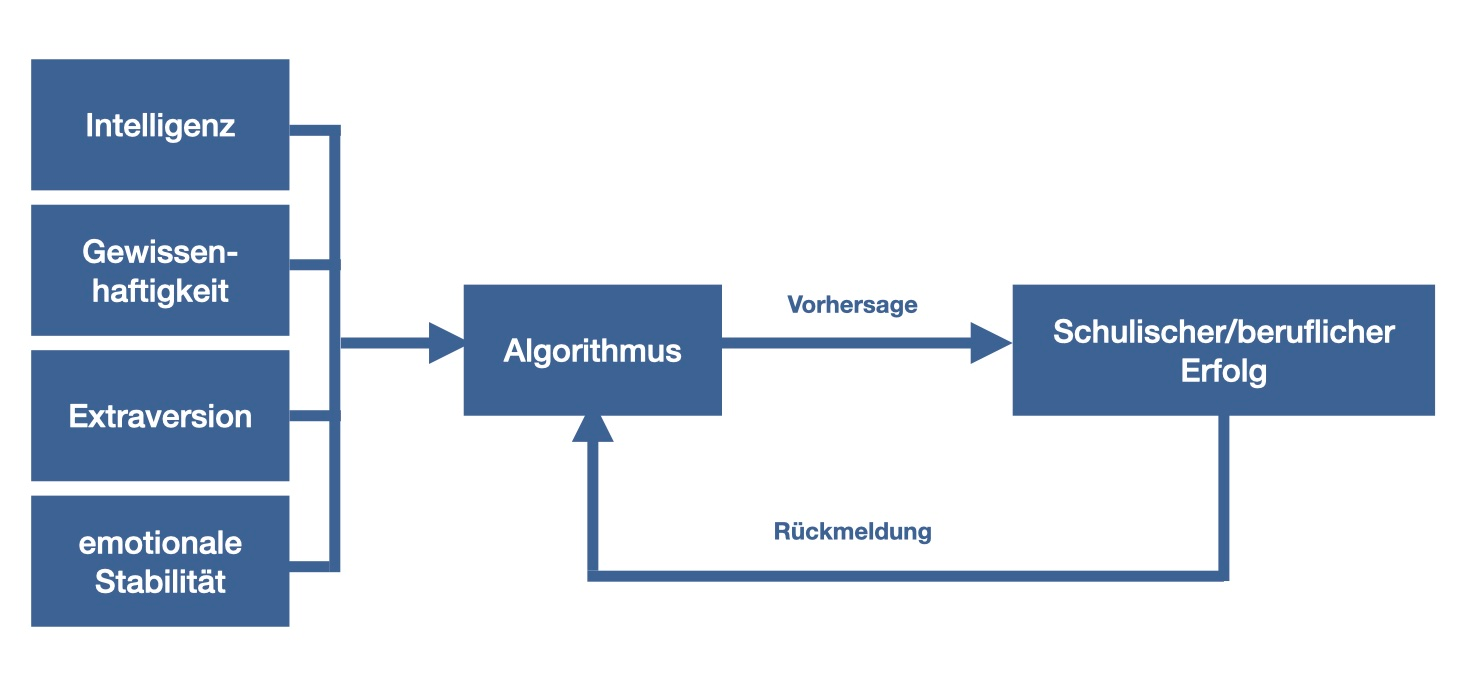
Allerdings gibt es außer Intelligenz noch weitere Kompetenzen, die auf den Berufserfolg Einfluss haben – z. B. Persönlichkeitseigenschaften wie Gewissenhaftigkeit, Extraversion oder emotionale Stabilität – das ist aus der Forschung bekannt. Für die Auswahl von geeigneten Bewerbern sieht die Formel also komplexer aus:

Abgesehen davon fließen diese vier Komponenten nicht gleichgewichtig in die Formel ein. Aus der Forschung weiß man z. B., dass Extraversion eine wichtige Eigenschaft ist, allerdings hat Intelligenz einen stärkeren Einfluss als Extraversion. Also muss man die vier Kompetenzen gewichten.
Lernende Algorithmen
Die Gewichtung kann man natürlich aus dem Bauch heraus festlegen, aber besser wäre es, Komponenten auf Grund der vorhandenen Daten so zu gewichten, dass der Berufserfolg möglichst genau vorhergesagt werden kann. Dazu gibt es ein Rechenverfahren (die sogenannte „Multiple Regression“), die diese Gewichtung auf mathematischem Wege vornimmt.
In der Praxis will man diesen Algorithmus jedoch permanent weiter optimieren, auf Basis der neu hinzukommenden Daten. Zum Beispiel stellt man Mitarbeiter aufgrund des Algorithmus ein und lässt das Potenzial der Mitarbeiter später von deren Vorgesetzten schätzen. Diese Vorgesetzteneinschätzung fließt dann in den Algorithmus ein und die Gewichtung der vier Komponenten wird weiter optimiert, sodass man bei den nächsten Bewerbern einen leicht verbesserten Algorithmus anwenden kann.
Das nennt man dann Machine Learning, d.h. der Algorithmus verfeinert sich automatisch durch die Rückmeldung durch die Vorgesetzten:
Neuronale Netze
Je komplexer die Daten über Bewerber sind, die man zur Verfügung hat, desto schwieriger ist die mathematische Berechnung des optimalen Algorithmus zur Auswahl. In der Künstlichen Intelligenz gibt es deshalb die Methode der Neuronalen Netze – ähnlich dem menschlichen Nervensystem konstruiert man auf dem Computer ein Netz mit verschiedenen Ebenen von Neuronen.
Dieses wird dann mit Informationen „gefüttert“, um zu lernen, bestimmte Muster zu „erkennen“. Bekanntestes Beispiel sind Neuronale Netze, die erkennen, ob auf einem Bild eine Katze zu sehen ist oder nicht. Das System „lernt“ diese Erkennung anhand eines großen Datensatzes (den sogenannten Trainingsdaten) von Bildern, diese Bilder enthalten die Information, ob darauf eine Katze zu sehen ist oder nicht.
Das Neuronale Netz hat anfangs nur Zufallstreffer, lernt aber aus jeder Rückmeldung („Katze richtig/falsch erkannt“), welche Bildbestandteile für eine Katze typisch sind, und kann dann irgendwann auf neuen Bildern, die nicht gekennzeichnet sind, Katzen erkennen.
Neuronale Netze in der Personalauswahl – viel Lärm um nichts
Die Idee liegt nahe, das Prinzip der Neuronalen Netze in der zur Auswahl von Personal anzuwenden: Man füttert das System mit allen verfügbaren Daten von bereits vorhandenen Mitarbeitern und versieht sie mit einem Etikett, ob der jeweilige Mitarbeiter ein Leistungsträger ist oder nicht. Daraus „lernt“ das System, Potenzial in Mitarbeitern zu identifizieren – und wendet das Neuronale Netz dann zukünftig bei der Einstellung oder Beförderung von Mitarbeitern zur Auswahl an.
Neuronale Netze verfestigen Vorurteile
So verlockend es ist, Neuronale Netze zur Personalauswahl anzuwenden – in der Praxis sind damit erhebliche Risiken verbunden. So haben wir bei md im Laufe unserer 35 Jahre Erfahrung viele Daten über Menschen im gehobenen Management gesammelt. Würde man ein Neuronales Netz mit diesen Daten füttern, würde das System folgendes über die Charakteristika erfolgreicher Manager lernen: sie sind männlich, weiß, zwischen 45 und 55 Jahre alt, überdurchschnittlich intelligent und leistungsmotiviert.
Während Intelligenz und Leistungsmotivation bekannt wichtige Eigenschaften von Managern sind, spiegeln die soziographischen Faktoren lediglich die vorhandenen Vorurteile wider, die jedoch keinen Einfluss auf die Leistungsfähigkeit haben.
Neuronale Netze statt Tests oder Bewerbungsgesprächen
Im Rahmen der anfänglichen Euphorie über die Möglichkeiten der künstlichen Intelligenz kamen in den letzten Jahren zahlreiche KI-gestützte Verfahren und Tests auf den Markt, die Sprache, ein Videointerview und/oder ein Bild eines Bewerbers analysieren. Die Anbieter versprachen, mit Hilfe der KI auf Basis einer relativ kurzen Videosequenz Aussagen über Persönlichkeit, kognitive Fähigkeiten und die Eignung von Bewerbern machen zu können.
In der Tat wird jedes Neuronale Netz in der Lage sein, aus einem Trainingsdatensatz von Bewerbervideos und den dazugehörenden Daten über psychologische Eigenschaften zu „lernen“, welche Bild- und Toninformationen im Trainingsdatensatz mit welchen Persönlichkeitseigenschaften zusammenhängen. Das ist allerdings nicht mehr als ein Zufallsergebnis – ähnlich als wenn man ein Neuronales Netz mit Wetterinformationen und Fußballergebnissen füttert, auch hier wird das System bestimmte Regeln erkennen.
Die Vorhersagen, die das System dann aber für neue Daten macht, werden nicht mehr als Zufallstreffer sein.
Der Bayerische Rundfunk hat z. B. vor einigen Jahren einen solchen Anbieter überprüft, der mit Hilfe von Künstlicher Intelligenz Videointerviews auswerten sollte. Dort wurde festgestellt, dass die Einschätzung einer Person anders ist, je nachdem ob eine Bücherwand (positiv) oder ein unaufgeräumtes Zimmer (negativ) im Hintergrund zu sehen ist.
Auch wenn einige Unternehmen solche KI-basierten Auswahlverfahren eingesetzt haben, kann man heute feststellen, dass diese keine verwertbaren Aussagen über Menschen produzieren – sei es, dass sie auf Videomaterial, Gesichtern oder der Auswertung von Sprache (sogenannte „Word Count Analysis“) basieren.
Unseriöse Verfahren auf KI-Basis
Künstliche Intelligenz kann keine Wunder vollbringen. Alle Verfahren, die versprechen, auf Basis weniger Bild- oder Sprachinformationen Einschätzungen von Menschen vornehmen zu können, haben sich als nicht nachhaltig erwiesen.
So gab es in der Wissenschaft Beispiele für Studien, bei denen Neuronale Netze auf Basis von Portraitfotos die sexuelle oder politische Orientierung von Menschen erstaunlich häufig (sprich: etwas häufiger als nach dem Zufall zu erwarten wäre) identifizieren konnten.
Da Neuronale Netze den Charakter einer „Black Box“ haben (man kann im Nachhinein nicht mehr feststellen, auf welcher Basis die KI zu der Einschätzung gekommen ist), ist es nicht einfach, die Mechanismen der KI zu überprüfen.
Im Fall der sexuellen oder politischen Orientierung stellte sich später heraus, dass es nicht die Gesichter an sich waren, die zu der Einordnung geführt haben, sondern andere Informationen im Bild selbst oder in den Metadaten – wie Schminke, Schmuck, Bilder im Hintergrund oder der Ort, an dem das Foto gemacht wurde (im Süden der USA sind die Menschen konservativer als an der Ost- und Westküste).
Deshalb ist große Vorsicht geboten gegenüber neuen KI-gestützten Verfahren in der Personalauswahl – keines der in den letzten Jahren auf den Markt gekommenen Verfahren hat einer sorgfältigen wissenschaftlichen Überprüfung standgehalten
Ausblick: Künstliche Intelligenz sinnvoll angewendet
Anders sieht das in zwei anderen Bereichen aus, in denen KI und Algorithmen durchaus vielversprechend eingesetzt werden können.
Big Data
Interessant ist der Ansatz, die in Unternehmen vorhandenen umfangreichen Daten über Mitarbeiter zu nutzen. Durch die fortschreitende Digitalisierung der Arbeitsabläufe haben Unternehmen viele Daten über Verhalten von Mitarbeitern – wer mit wem Nachrichten austauscht, wie häufig bestimmte Informationen abgerufen werden, welchen Tätigkeiten die Mitarbeiter nachgehen. Diese Daten können zur Bewertung von Mitarbeitern, aber auch zur Identifikation von Entwicklungsfeldern genutzt werden.
Natürlich ist der Schritt von „Big Data“ zu „Big Brother“ nicht groß und zurecht regt sich Widerstand dagegen, das Verhalten und die Leistung von Mitarbeitern dermaßen transparent zu machen. Auf der anderen Seite ist die Beurteilung von Leistung und das Identifizieren von Leistungsdefiziten etwas, das – auch ohne KI – in jedem Unternehmen stattfindet; meistens jedoch auf der Basis von eher subjektiven Informationen (persönliche Einschätzung des Vorgesetzten) als von objektiven Daten.
Matching statt Auswahl
Ein anderer interessanter Ansatz besteht darin, Algorithmen nicht zur Auswahl, sondern zum Matching von Interessenten zu Jobs einzusetzen. Das Unternehmen JobMatchMe hat sich beispielsweise das Ziel gesetzt, es im Bereich der nicht-akademischen Fachkräfte den Interessenten einfacher zu machen, für sie passende Jobs zu finden.
Gerade in den sogenannten Mangelberufen (Lkw-Fahrer, Pflegekräfte, Gastronomie) ist es – paradoxerweise – für Fachkräfte, die einen neuen Job suchen, nicht einfach, den für sie passenden Arbeitgeber zu finden. Aufgrund der Vielzahl der offenen Stellen müssten sie viele Bewerbungen schreiben, um dann häufig erst im Bewerbungsgespräch festzustellen, ob der Job wirklich zu ihren Wünschen und Fähigkeiten passt. Alleine das Erstellen der Bewerbungsunterlagen ist ein sehr zeitaufwändiger Prozess, der für Nicht-Akademiker noch schwierige ist als für andere Arbeitnehmer.
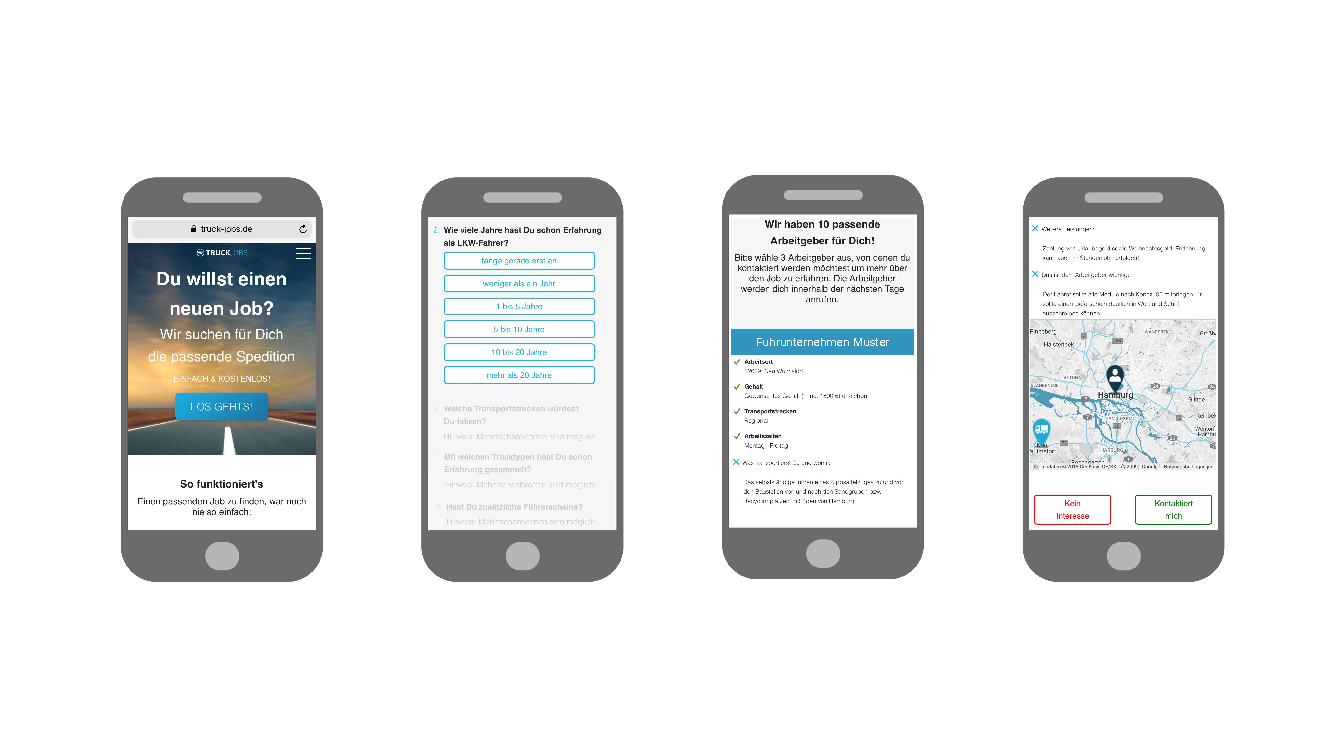
JobMatchMe hat den Prozess so verschlankt, dass Arbeitnehmer in nur 10 Minuten die notwendigen Informationen („Was suchst Du?“, „Was bietest Du?“, „Wie tickst Du?“) eingeben, um dann sofort in Kontakt mit für sie passenden Arbeitgebern zu kommen (unten am Beispiel von Lkw-Fahrern):
Ein Algorithmus sorgt dafür, dass den Interessenten nur die für sie passenden Jobs präsentiert werden:
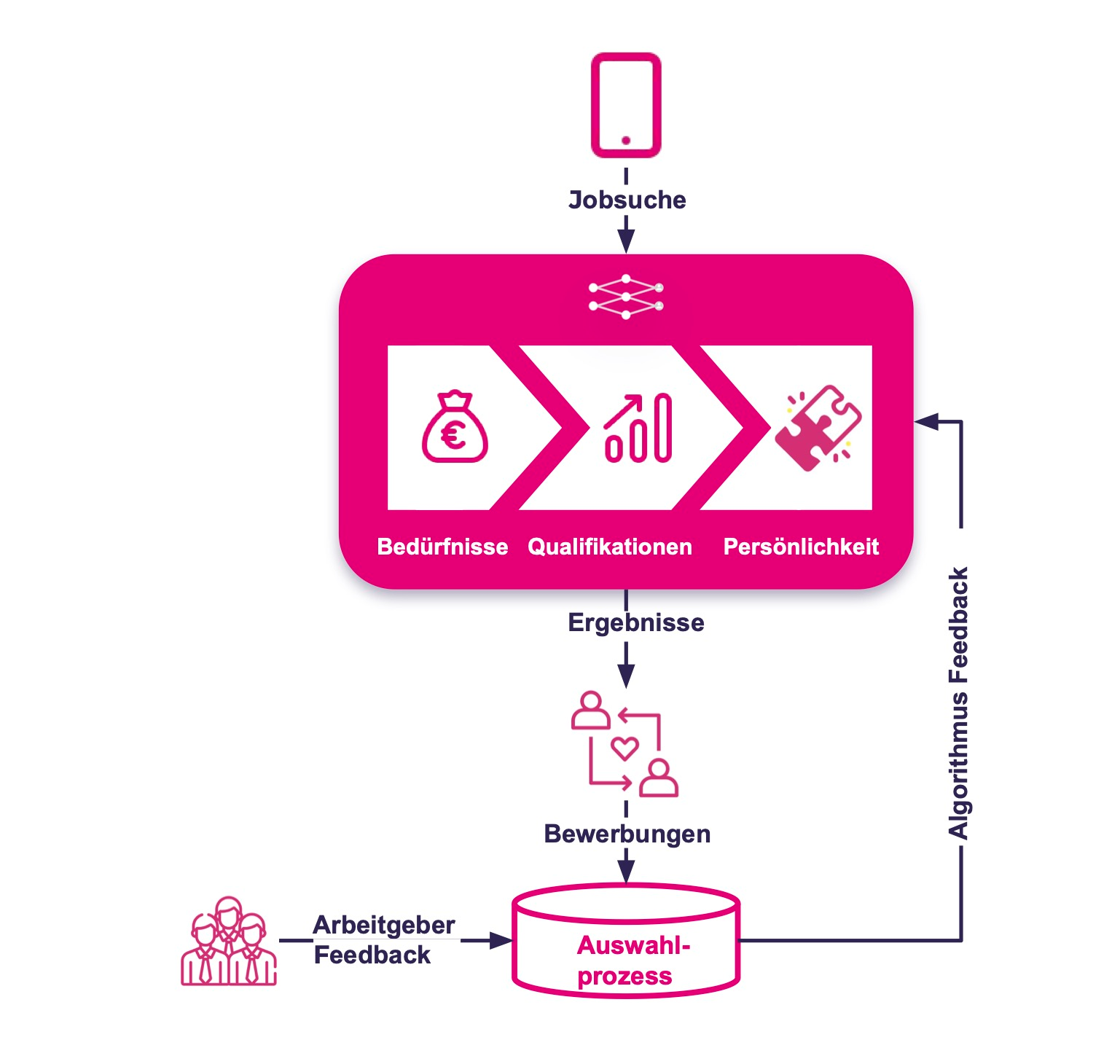
Dieser Form des intelligenten Matchings könnte auch in anderen Bereichen eingesetzt werden – etwa für unternehmensinterne Jobbörsen oder die Vermittlung von ausländischen Arbeitnehmern nach Deutschland.
Chancen und Risiken der Künstlichen Intelligenz in der Personalauswahl
Chancen
große Datenmengen über Verhalten von Mitarbeitenden (Big Data) können für objektive Bewertung der Leistung und Potenziale der Mitarbeitenden genutzt werden
Durch Bewertung von Mitarbeitenden auf Basis der häufig schon in verschiedenen Systemen vorhandenen Verhaltensdaten können Entwicklungsfelder identifiziert und Mitarbeitende gezielt gefördert werden
bei einer großen Anzahl von Interessenten (Arbeitnehmern) und Aufgaben (Arbeitgeber) können Algorithmen helfen, beide Seiten miteinander zu matchen (Passung statt Eignung)
Risiken
zahlreiche neue Anbieter bieten Auswahlverfahren an, die auf Künstlicher Intelligenz basieren und die angeblich mit wenig Aufwand zu treffsicheren Einschätzungen von Menschen kommen – bisher haben sich all diese Verfahren jedoch als wenig valide und wissenschaftlich unseriös erwiesen
da Verfahren, die auf Deep Learning und Neuronalen Netzen basieren, eine Black Box darstellen, lässt sich nicht überprüfen, ob die Algorithmen sinnvolle Verknüpfungen bilden oder lediglich auf das Trainingsmaterial optimiert sind
Auswahlverfahren, die auf Deep Learning basieren, verfestigen häufig schon existierende Vorurteile und Biases (z.B. gegenüber Frauen und Minoritäten)
für Nutzer (Personaler und Entscheider) sind Auswahlentscheidungen auf Basis Neuronaler Netzer und Machine Learning eine Black Blox, sie erkennen also nicht die Grenzen der Künstlichen Intelligenz

















